什么是dom4j
Dom4j是一个易用的、开源的库,用于XML,XPath和XSLT。它应用于Java平台,采用了Java集合框架并完全支持DOM,SAX和JAXP。
以上来自百度百科,不过dom4j的词条感觉是来自某个博客。国内关于dom4j的东西还是蛮少的,或者说关于XML解析的资料就很少。这个博文也是大概写一下dom4j的入门使用。推荐看官方的快速入门文档,简单粗暴易懂:
DOM、SAX与dom4j
DOM和SAX都是Java关于XML解析的底层API,所在的包分别是:
- DOM: org.w3c.dom
- SAX: org.xml.sax
这里就能看出一点不同了,DOM的包是跟w3c有关的,而SAX则更像Java原生的API。
DOM是W3C的标准,学过前端的同学对于DOM非常熟悉,而这个DOM与XML的DOM是完全一致的,是w3c为了跨平台、语言所设定的标准。
SAX的全名是“simple API for XML”,可以说是为解析XML而生了。
DOM
文档对象模型,整体获取整个文档对象之后,对其中的各个元素进行操作。对于XML和HTML是一样的。
对于一个文档,生成了一个DOM树的结构,例如这样的XML文件:
1
2
3
4
5
6
7
8
9
10
11
<?xml version="1.0" encoding="GBK"?>
<root>
<list>
<name>iwts</name>
<number>001</number>
</list>
<list>
<name>ashen one</name>
<number>002</number>
</list>
</root>
生成了这样的DOM树
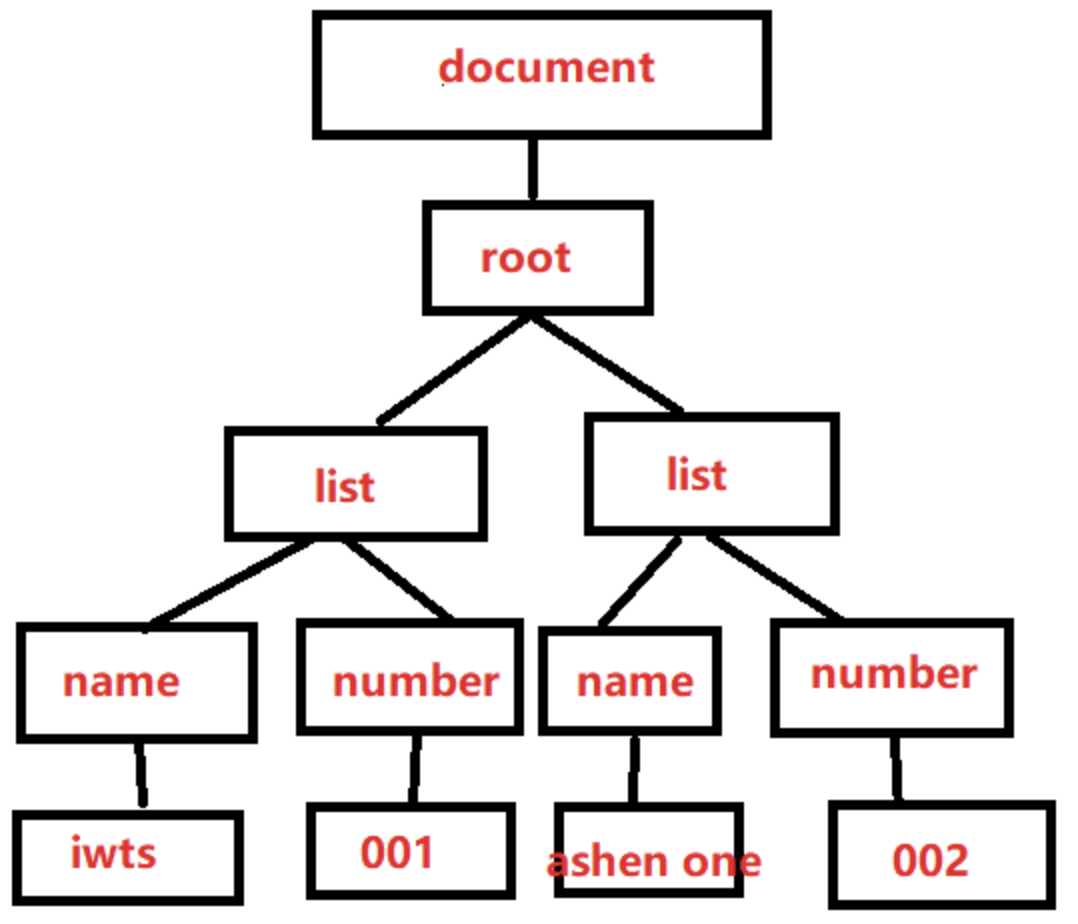
然后,我们就可以找到确定的元素,Element,并且对其添加元素或者删除元素,以及修改数据。
在解析的时候,DOM解析是直接分析整个XML文件,并且生成结点。所以一般适用于小文件,否则大文件解析的时间会略长。影响效率。
SAX
SAX 则是跟DOM完全相反,SAX是基于事件解析。或者说,SAX是顺序执行整个文档,不管文档有多大,都从第一行开始慢慢往下解析。
这样就解决了DOM解析的缺点:对于大文档效率过低。但是也失去了任意访问元素的方便性.
同时,为了效率,SAX解析是不会储存已经解析出来的元素的。所以在碰到需要的元素的时候,程序员需要手动来储存这个元素。
基于DOM和SAX的开源组件
DOM与SAX各有各的优势,DOM适合大量修改数据的情况,而SAX则胜在效率高。两者不是互斥的,我们可以结合两者来完成对XML的解析。
所以就催生了dom4j、jdom以及其他类似的技术。
dom4j下载与部署
其实就是下载一个jar包并在项目中引用,dom4j在GitHub上开源,可以直接去下载。
或者访问 dom4j 选择版本下载。
下载直接就是一个jar包了。具体怎么使用根据IDE的不同是不一样的。下面介绍idea的使用:
- 右上角File->Project Structure->Project Settings->Modules
- 窗口右侧Dependencise
- 窗口最右边有一个绿色的加号,点击加号并选择“JARs or directorise..”,在电脑中选择下载的jar包就可以了。
- 在窗口jar包左侧勾选该jar包,点击apply就完事了。
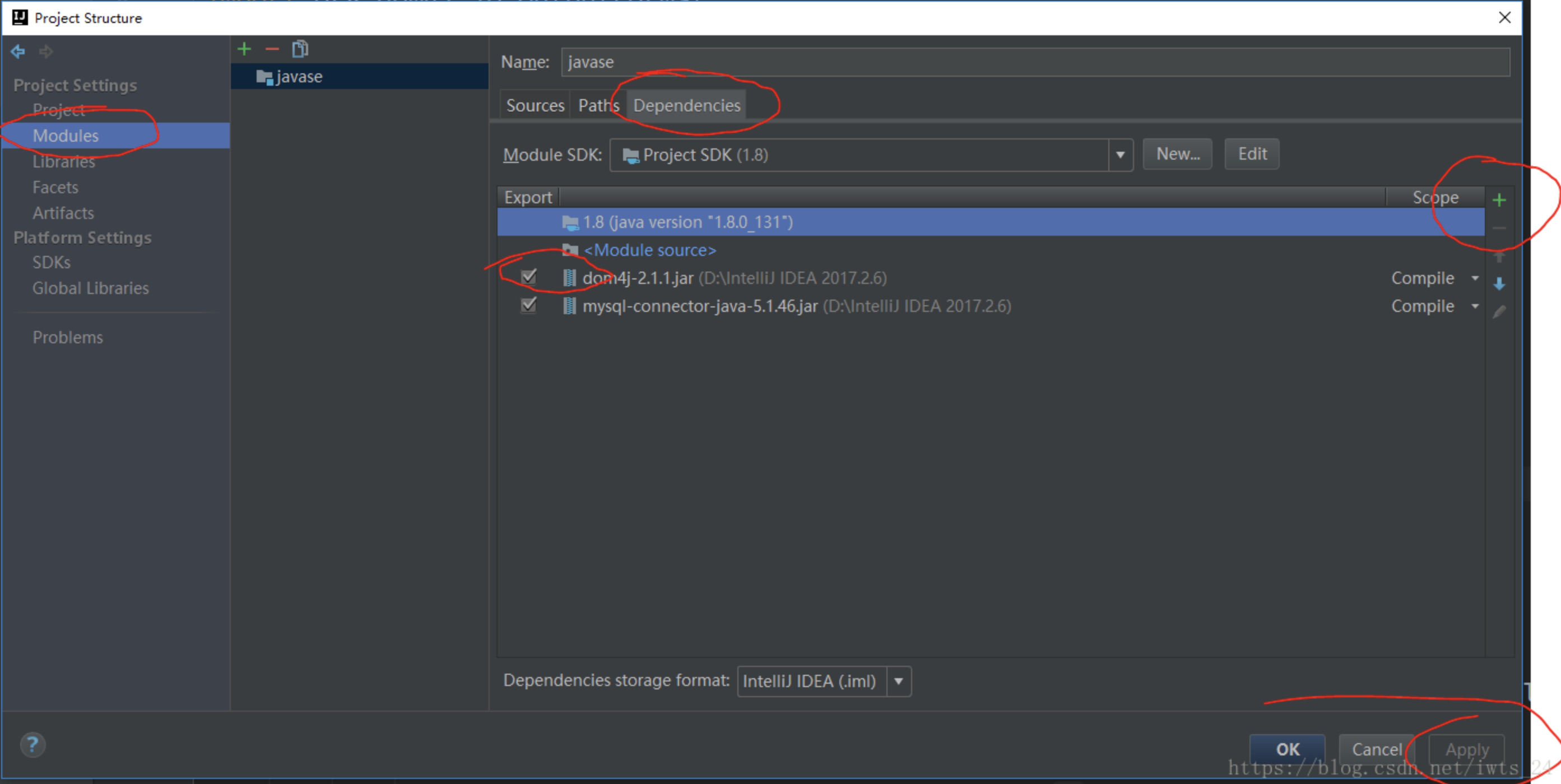
来自2024年的review
这是上大学的博客哈哈,那时候图样图森破,实际上Java的话使用Maven直接管理是最好的,下载jar包这太old school了
dom4j解析XML文件
先上代码:
1
2
3
4
5
6
7
public class Main {
public static void main(String[] args) throws Exception{
File file = new File("./test.xml");
SAXReader reader = new SAXReader();
Document doc = reader.read(file);
}
}
利用SAX来解析XML,但是又生成了DOM的document结点,这样我们就可以利用DOM来操作具体的元素。例如我们遍历输出XML文件所有数据。
而由于我们生成了DOM树,所以利用迭代器来控制整个文档非常方便 ,对于root结点生成迭代器,那么迭代的内容就是所有子结点。放在树数据结构上说,就是迭代了所有的儿子。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
public class Main {
public static void main(String[] args) throws Exception{
File file = new File("./test.xml");
SAXReader reader = new SAXReader();
Document doc = reader.read(file);
Element root = doc.getRootElement();
Iterator it = root.elementIterator();
while(it.hasNext()){
Element list = (Element) it.next();
System.out.println("name: "+list.elementText("name")+" number: "+list.elementText("number"));
}
}
}
Docunment & Element
根据以上代码介绍一下dom4j的主要的2个类:
- Document
- Element
构造出DOM树以后,就生成了一个Docunment对象,可以参考上面的DOM树的图,Document的方法Element getRootElement()则返回根节点的对象。
DOM树中所有的对象都是类Element,Iterator<E> elementInerator()方法生成迭代器,elementText(String elem)方法则输出该元素的elem儿子的数据。
数据修改
上面是遍历,那么我们也可以对数据进行修改。这就要求我们能获取到确定的一个元素,并且修改。
如果是一个大的文档,我们需要去查找,因为是树结构,我们可以利用DFS或者BFS来查找。这就涉及到具体的查找算法了,下面是简单的,修改一个数据。具体的查找算法与dom4j技术无关。</p>
package me.iwts;
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import java.io.File;
import java.util.Iterator;
public class Main {
public static void main(String[] args) throws Exception{
File file = new File("./test.xml");
SAXReader reader = new SAXReader();
Document doc = reader.read(file);
Element root = doc.getRootElement();
Iterator it = root.elementIterator();
while(it.hasNext()){
Element list = (Element) it.next();
System.out.println("name: "+list.elementText("name")+" number: "+list.elementText("number"));
Element name = list.element("name");
name.setText("alert");
System.out.println("new name: "+list.elementText("name"));
}
}
}
Element类的Element element(String elem)方法是对于该元素,获取其elem子元素的对象。然后可以利用void setText(String str)方法来修改数据。
创建一个XML文档
纯粹解析XML文档是不够的,应该能利用数据来生成XML文件。或者说这样是相对用的更多的技术。例如表单获取的数据,可以先储存在XML中。 ```java public class Main { public static void main(String[] args) throws Exception{ File file = new File("./test.xml"); SAXReader reader = new SAXReader(); Document doc = reader.read(file); Element root = doc.getRootElement(); Iterator it = root.elementIterator(); while(it.hasNext()){ Element list = (Element) it.next(); System.out.println("name: "+list.elementText("name")+" number: "+list.elementText("number")); Element name = list.element("name"); name.setText("alert"); System.out.println("new name: "+list.elementText("name")); } } } ``` ## 数据添加 利用```DocumentHelper```的静态方法```createDocument```可以创建一个Document对象,也就是一个空的XML,这样有了Document对象就可以在其中添加各种各样的元素了。 对于Document对象和Element对象,```Element addElement(String elem)```方法是在该元素下添加一个元素,并且返回这个元素的实例。 对于可以添加数据的元素而言,我们可以在获取实例之后,利用```setTest()```方法添加数据。 ## 从数据源创建XML对象 一般地,我们不会创建很少的结点,所以一般都是利用while循环或者for循环来控制。例如从键盘读取数据,那么: ```java Scanner input = new Scanner(System.in); while(input.hasNext()) { Element list = root.addElement("list"); list.addElement("name").setText(input.next()); list.addElement("number").setText(input.next()); } ``` 同样,从数据库读入也是很常见的,利用while循环也是类似的写法。 以上只是生成了一个确定的Document对象,此时这个对象就是刚从XML解析获得的对象一样。实际上我们还应该在具体的路径下生成一个对应的XML文件。 ```java import org.dom4j.Document; import org.dom4j.DocumentHelper; import org.dom4j.Element; import org.dom4j.io.OutputFormat; import org.dom4j.io.XMLWriter; import java.io.File; import java.io.FileOutputStream; public class Main { public static void main(String[] args) throws Exception{ Document doc = DocumentHelper.createDocument(); Element root = doc.addElement("root"); Element list1 = root.addElement("list"); list1.addElement("name").setText("iwts"); list1.addElement("number").setText("001"); Element list2 = root.addElement("list"); list2.addElement("name").setText("ashen one"); list2.addElement("number").setText("002"); OutputFormat format = OutputFormat.createPrettyPrint(); format.setEncoding("GBK"); File file = new File("./test.xml"); XMLWriter write = new XMLWriter(new FileOutputStream(file),format); write.write(doc); write.close(); } } ``` OutputFormat以及XMLWriter都是属于dom4j的,加载包的时候注意不要加错。 format是一定要的,并且可以设置的参数有很多,常用的还是设定编码。 XMLWriter对象,声明了以何种格式将Document对象转化为XML文件存放在哪个路径中,是可以多次利用的对象。其```void write(Document doc)```方法,加载一个DOM对象,并在规定的路径下生成XML文件。